「黑马点评」九、好友关注
关注和取关
关注、取关用户:PUT /api/follow/{userId}/{true/false}
判断是否关注:GET /api/follow/or/not/{userId}
数据库建关联表
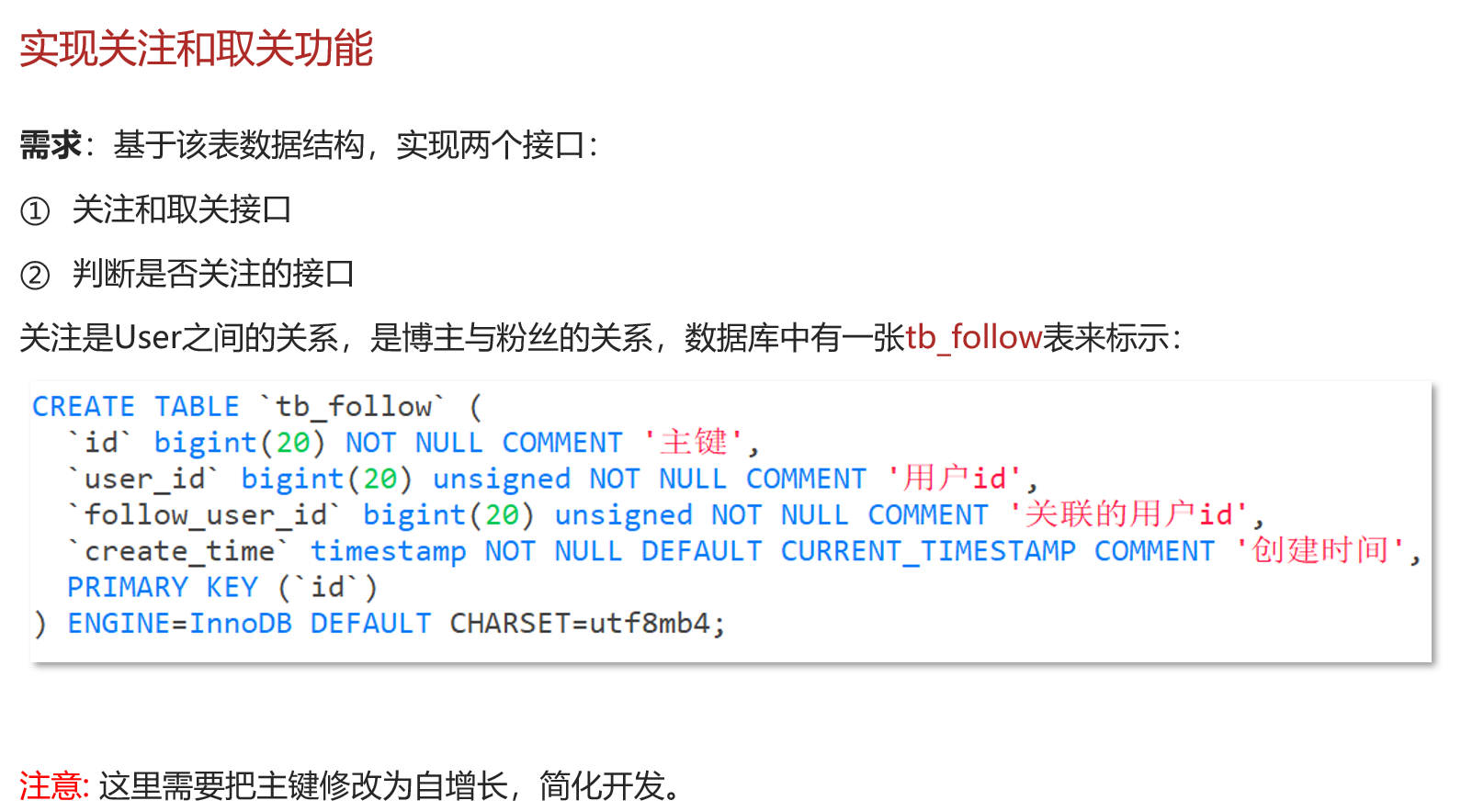
image.png|500
非常基础的实现
@Service
public class FollowServiceImpl implements IFollowService {
@Resource
private FollowMapper followMapper;
@Override
public Result<String> follow(Long followUserId, Boolean isFollow) {
Long userId = UserHolder.getUser().getId();
if(isFollow) {
Follow follow = new Follow();
follow.setUserId(userId);
follow.setFollowUserId(followUserId);
followMapper.insert(follow);
} else {
followMapper.deleteByUserIdAndFollowUserId(userId, followUserId);
}
return Result.success("success");
}
@Override
public Result<Boolean> isFollow(Long followUserId) {
Long userId = UserHolder.getUser().getId();
Follow follow = followMapper.selectByUserIdAndFollowUserId(userId, followUserId);
return Result.success(follow != null);
}
}共同关注
共同关注在博主主页的分栏中第二位,路过了两个接口:
- 用户信息:GET
/api/user/{id} - 用户笔记:GET
/api/blog/of/user?&id={userId}¤t={currentPage}
基础实现
@GetMapping("/of/user")
public Result<List<Blog>> queryBlogByUserId(
@RequestParam(value = "current", defaultValue = "1") Integer current,
@RequestParam("id") Long id) {
// 根据用户查询
List<Blog> blogs = blogService.queryByUserId(id, current);
return Result.success(blogs);
}
@Override
public List<Blog> queryByUserId(Long userId, int current) {
// 计算偏移量
int offset = (current - 1) * SystemConstants.MAX_PAGE_SIZE;
List<Blog> blogs = blogMapper.selectByUserId(userId, offset, SystemConstants.MAX_PAGE_SIZE);
blogs.forEach(this::setUserInfo);
blogs.forEach(this::setIsLike);
return blogs;
}
@GetMapping("/{id}")
public Result<UserDTO> queryUserById(@PathVariable("id") Long userId) {
// 查询详情
User user = userService.getById(userId);
if (user == null) {
return Result.success(null);
}
UserDTO userDTO = BeanUtil.copyProperties(user, UserDTO.class);
// 返回
return Result.success(userDTO);
}查看与某用户的共同关注:GET /api/follow/common/{userId}
明显要用 Redis,SINTER 可以获得两个 SET 的交集
@GetMapping("/common/{id}")
public Result<List<UserDTO>> followCommons(@PathVariable("id") Long id) {
return followService.followCommons(id);
}
@Override
public Result<List<UserDTO>> followCommons(Long id) {
Long userId = UserHolder.getUser().getId();
String key = RedisConstants.FOLLOW_KEY + userId;
String key2 = RedisConstants.FOLLOW_KEY + id;
Set<String> intersect = stringRedisTemplate.opsForSet().intersect(key, key2);
if(intersect == null || intersect.isEmpty()) {
return Result.success(Collections.emptyList());
}
List<Long> ids = intersect.stream().map(Long::valueOf).collect(Collectors.toList());
List<User> users = userService.listByIds(ids);
List<UserDTO> userDTOs = users
.stream()
.map(user -> BeanUtil.copyProperties(user, UserDTO.class))
.collect(Collectors.toList());
return Result.success(userDTOs);
}关注推送
关注推送,Feed 流,推送关注用户的最新博文
常见模式:
- 时间线不做内容筛选,按照内容发布时间进行排序,常用于好友、关注,如朋友圈、动态
- 智能排序:搜广推
时间线 TimeLine 推送流 Feed 流实现方案
拉模式:也叫读扩散 每次读取时,拉取被关注者的消息,每份消息仅一份,但是每次拉取消耗过大

image.png|500
推模式:也叫写扩散 被关注者直接推送到关注者的收件箱内,内存占用高,每份消息重复多份
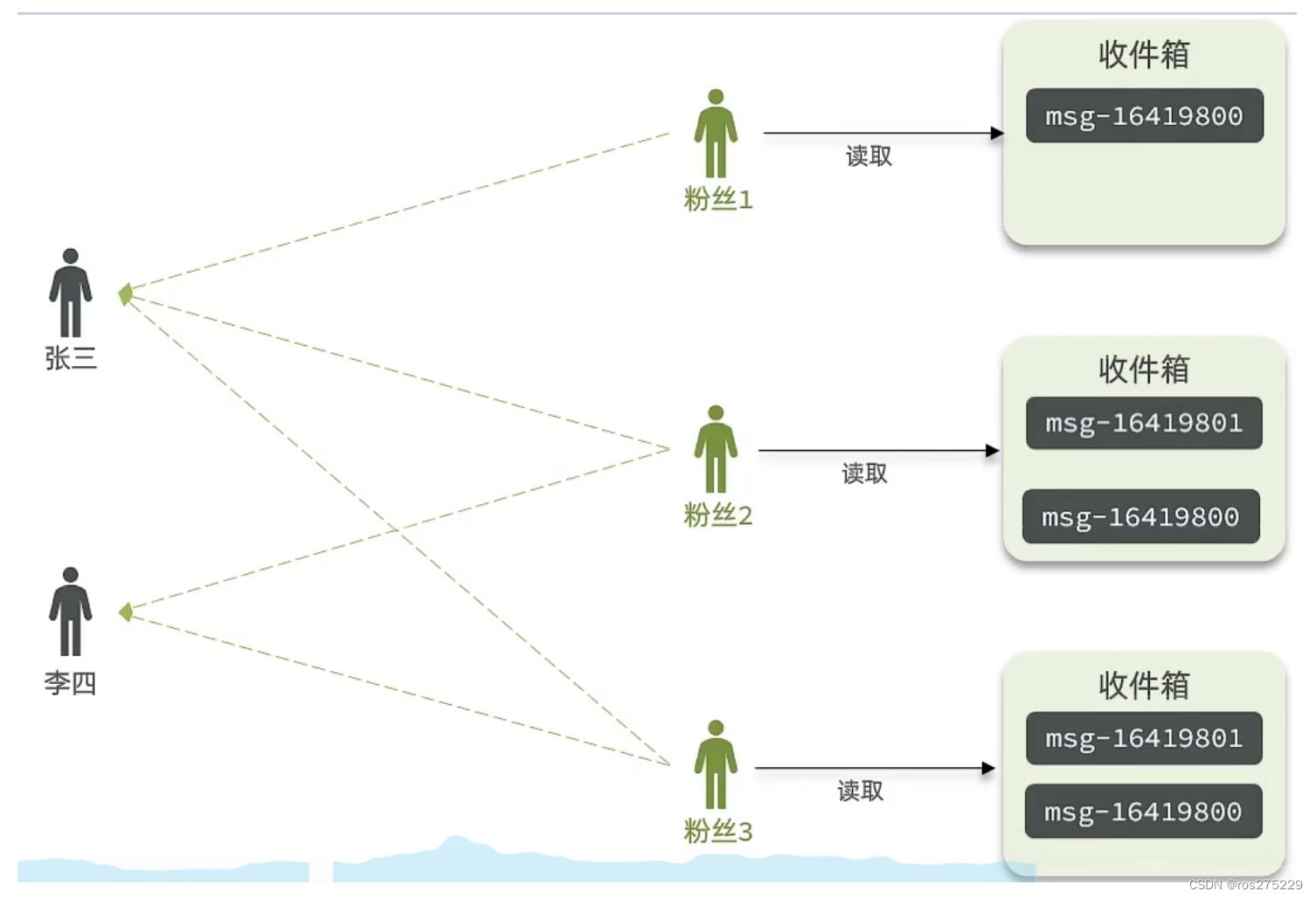
image.png|500
推拉结合模式:也叫读写混合 对于活跃粉丝采用推模式,对于普通粉丝采用拉模式 避免高频拉,以及无效推
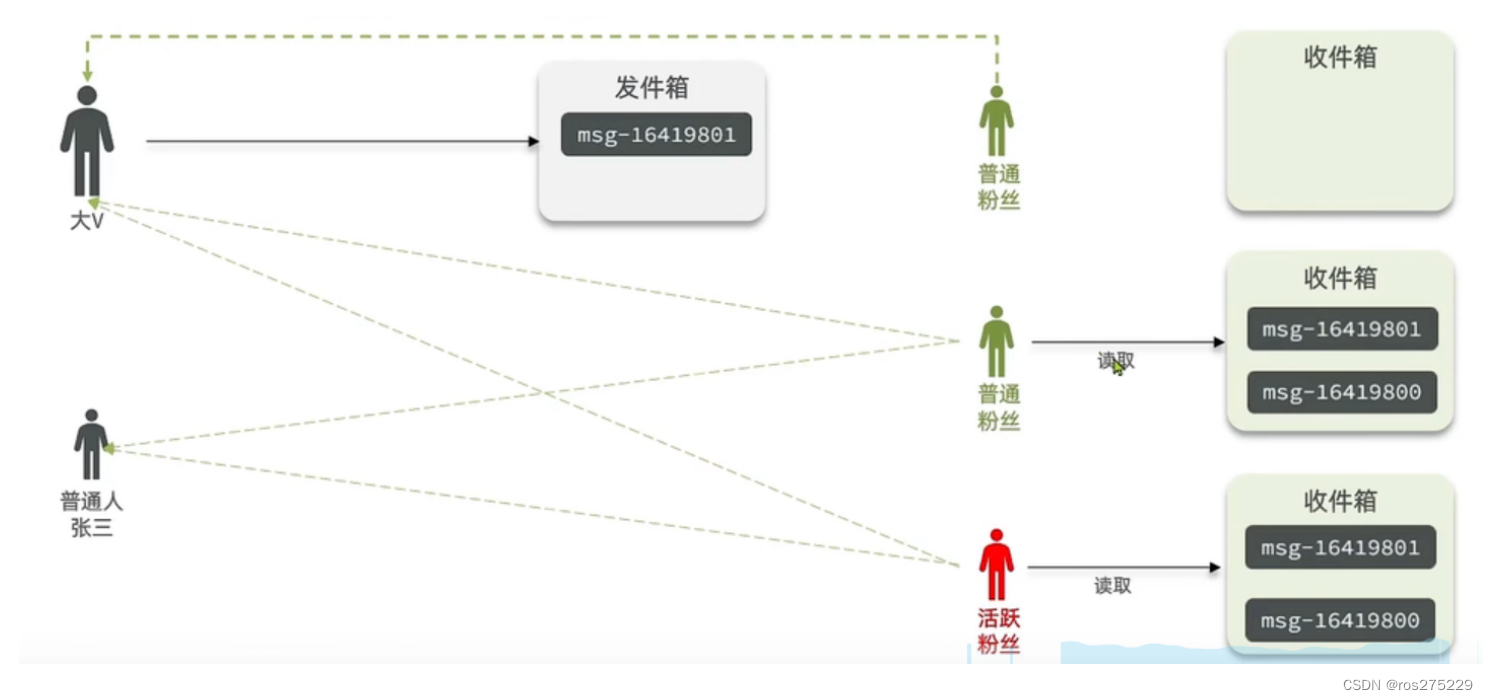
image.png|500
对比
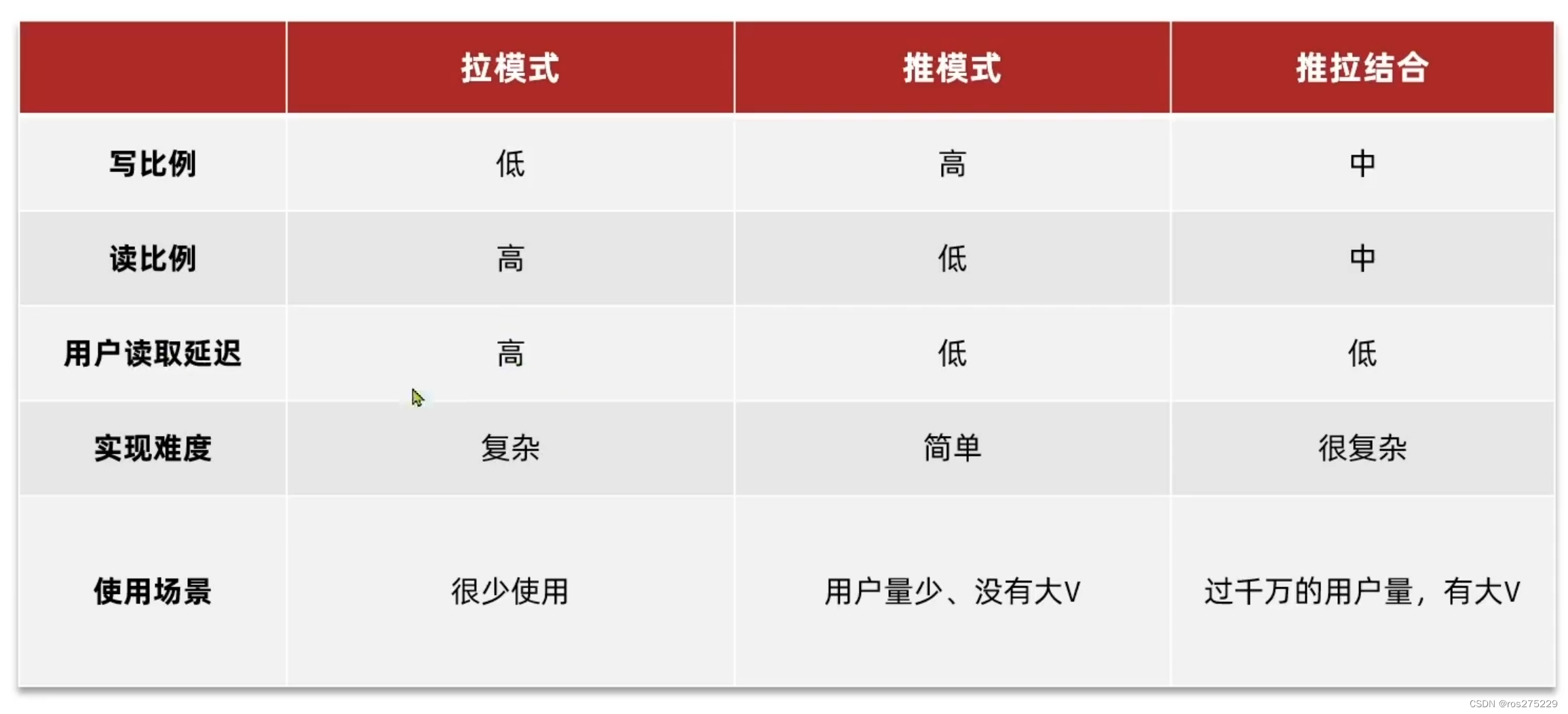
image.png|500
在黑马点评中,无高被关注者,千万数据一下,采用推模式
基于推模式实现关注推送功能
需求
- 修改新增笔记业务,保存 blog 到数据库同时,推送到粉丝的收件箱
- 收件箱按照时间戳排序,利用 Redis 实现
- 查询收件箱数据实现分页查询
既然已经实现了保存 blog 到数据库,所以只需要推送 blogId 即可
如果采用普通的分页,在查询时如果新增一条数据,那么角标就会受到影响,产生了重复读取
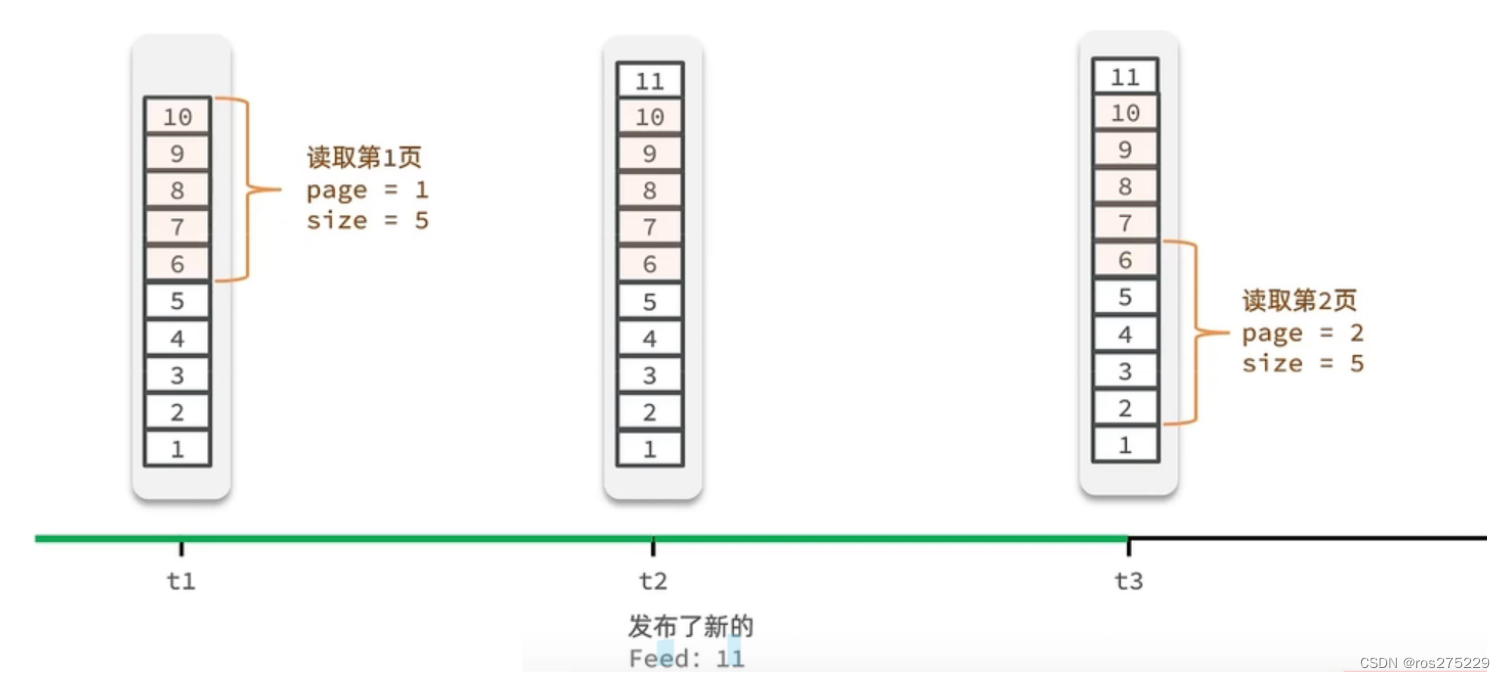
image.png|500
所以,这个场景下,应该是滚动分页技术,记录每次查询操作的最后一条,从这个位置继续读取数据,可以从无穷开始
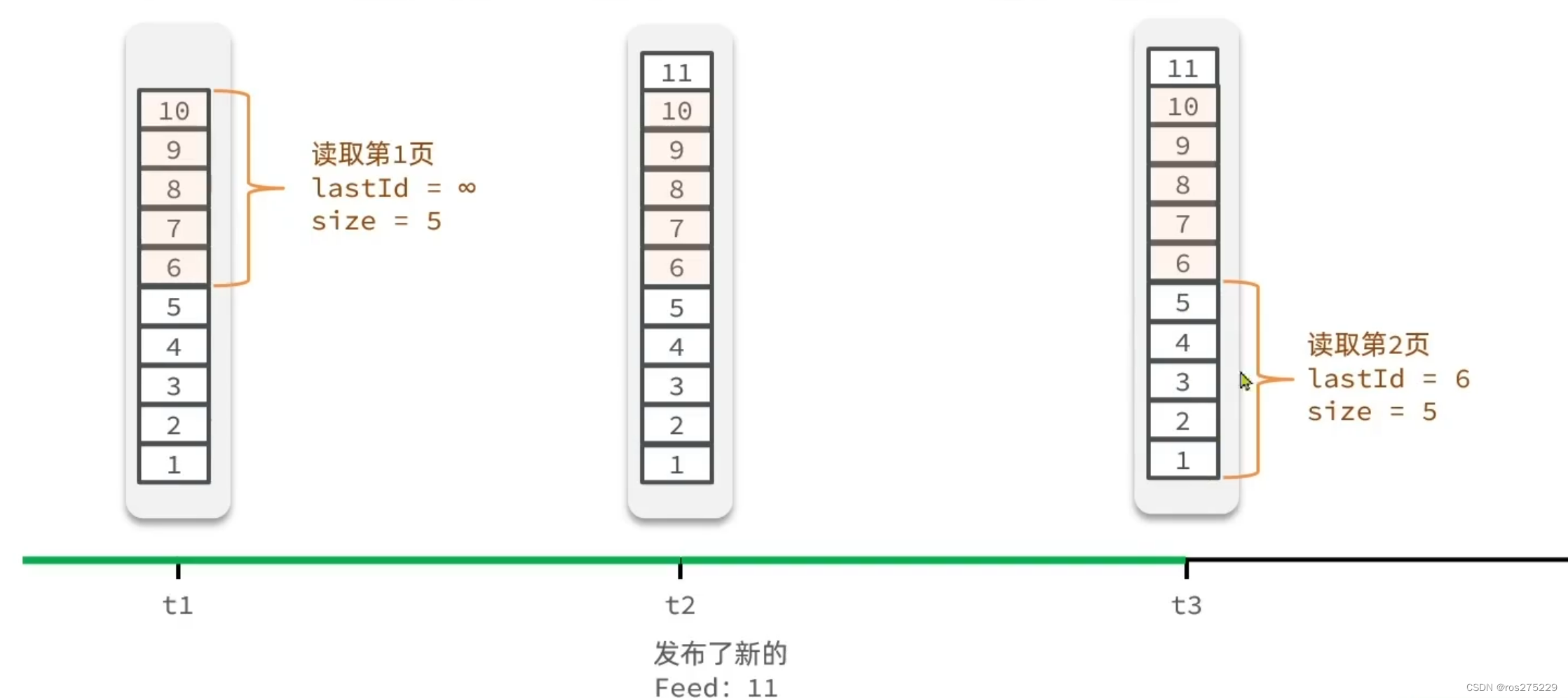
image.png|500
Redis 的 LIST 结构只能按照角标查询,所以无法支持滚动分页,而 SortedSet 可以使用 SRANGE 查询,支持滚动分页 > List 的角标无法支持滚动分页,记录角标不可行,因为如果新消息从头部插入会扰乱角标,而 ZSET 可以根据 score 定位,无视角标;下滑刷新新消息,上滑查看旧消息,滚动窗口即视感
发布 blog 时推送到关注者收件箱中
@Override
public String saveBlog(Blog blog) {
Long userId = UserHolder.getUser().getId();
blog.setUserId(userId);
boolean isSuccess = blogMapper.insert(blog) > 0;
if(!isSuccess) {
return "error";
}
List<Follow> follows = followMapper.selectByFollowUserId(userId);
for (Follow follow : follows) {
String key = RedisConstants.FEED_KEY + follow.getUserId();
stringRedisTemplate.opsForZSet().add(key, blog.getId().toString(), System.currentTimeMillis());
}
return "success";
}关注者在收件箱中分页查询被关注者发布的 blog:GET /api/blog/of/follow?&lastId={lastId}
ZREVRANGE setName minRank maxRank 降序获取 minRank - maxRank
ZREVRANGE z1 0 2 按照 score 从高到底获取第 0、1、2 位,当这时插入一条 score 最大的数据时再 ZREVRANGE z1 3 5 却会把之前的第 2 位重复查询,因为整体下移
利用 ZREVRANGEBYSCORE setName maxScore minScore WITHSCORES LIMIT offset[0,n] size 查询小于等于 maxScore(上次记录最后一名的值)的数据,且 offset=n 可以跳过上一次查询时与查询到的最后一名的值相同的数据的个数,避免重复查询
maxScore 当前时间戳,上一次查询时最小的时间戳,minScore 0
offset 上一次查询结果中,与最小值一样的元素的个数,用于跳过,避免重复查询
size 一次查询的数据量
注意数据库查询时,批量获取 blog 时,使用 where id in idsStr 无法保证顺序,所以还要使用 order by filed(id, idsStr) 保证顺序
@GetMapping("/of/follow")
public Result<ScrollResult<Blog>> queryBlogOfFollow(@RequestParam("lastId") Long lastId, @RequestParam(value = "offset", defaultValue = "0") Integer offset) {
return Result.success(blogService.queryBlogOfFollow(lastId, offset));
}
@Override
public ScrollResult<Blog> queryBlogOfFollow(Long lastId, Integer offset) {
Long userId = UserHolder.getUser().getId();
String key = RedisConstants.FEED_KEY + userId;
Set<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate.opsForZSet()
.reverseRangeByScoreWithScores(key, 0, lastId, offset, SystemConstants.MAX_PAGE_SIZE);
if(typedTuples == null || typedTuples.isEmpty()) {
return null;
}
List<Long> ids = new ArrayList<>(typedTuples.size());
long minTime = 0;
int os = 1;
for (ZSetOperations.TypedTuple<String> tuple : typedTuples) {
ids.add(Long.valueOf(tuple.getValue()));
if(tuple.getScore() == minTime) {
os++;
} else {
minTime = tuple.getScore().longValue();
os = 1;
}
}
List<Blog> blogs = blogMapper.selectList(ids);
blogs.forEach(this::setUserInfo);
ScrollResult<Blog> result = new ScrollResult<>();
result.setList(blogs);
result.setOffset(os);
result.setMinTime(minTime);
return result;
}